
Nhận diện kí tự trên ảnh (optical character recognition, viết tắt là OCR) có thể hình dung đơn giản là chúng ta chụp một bức ảnh ở đâu đó có chứa nội dung chữ, thì chương trình OCR đọc thay và trả ra chữ mà chúng ta có thể copy hoặc paste được trên máy tính.
Để làm được chương trình này thì chúng ta sẽ có thể sử dụng nhiều phương pháp như là API hoặc Engine nào đó như Tesseract. Tuy nhiên trong bài này, tôi sẽ sử dung phương pháp học sâu (Deep learning) cũng đồng thời là một nhánh của trí tuệ nhân tạo.
Hiển nhiên chúng ta sẽ đặt ra câu hỏi là bên trong chương trình nhận diện kí tự trên ảnh bằng phương pháp học sâu này là gì? Thì ở đây, nó sẽ có một số công việc như sau: xử lý ảnh để lấy thông tin, tiếp theo là từ những thông tin đó sẽ được xử lý để cho ra thông tin kí tự (như xác suất của một kí tự có thể xuất hiện ở một vị trí nào đó). Tuy nhiên những thông tin như thế này thì chỉ có máy mới hiểu, chứ người bình thường sẽ không hiểu được. Cho nên bước cuối cùng là sử dụng một thuật toán nào đó để giải mã nó ra kết quả mong muốn.
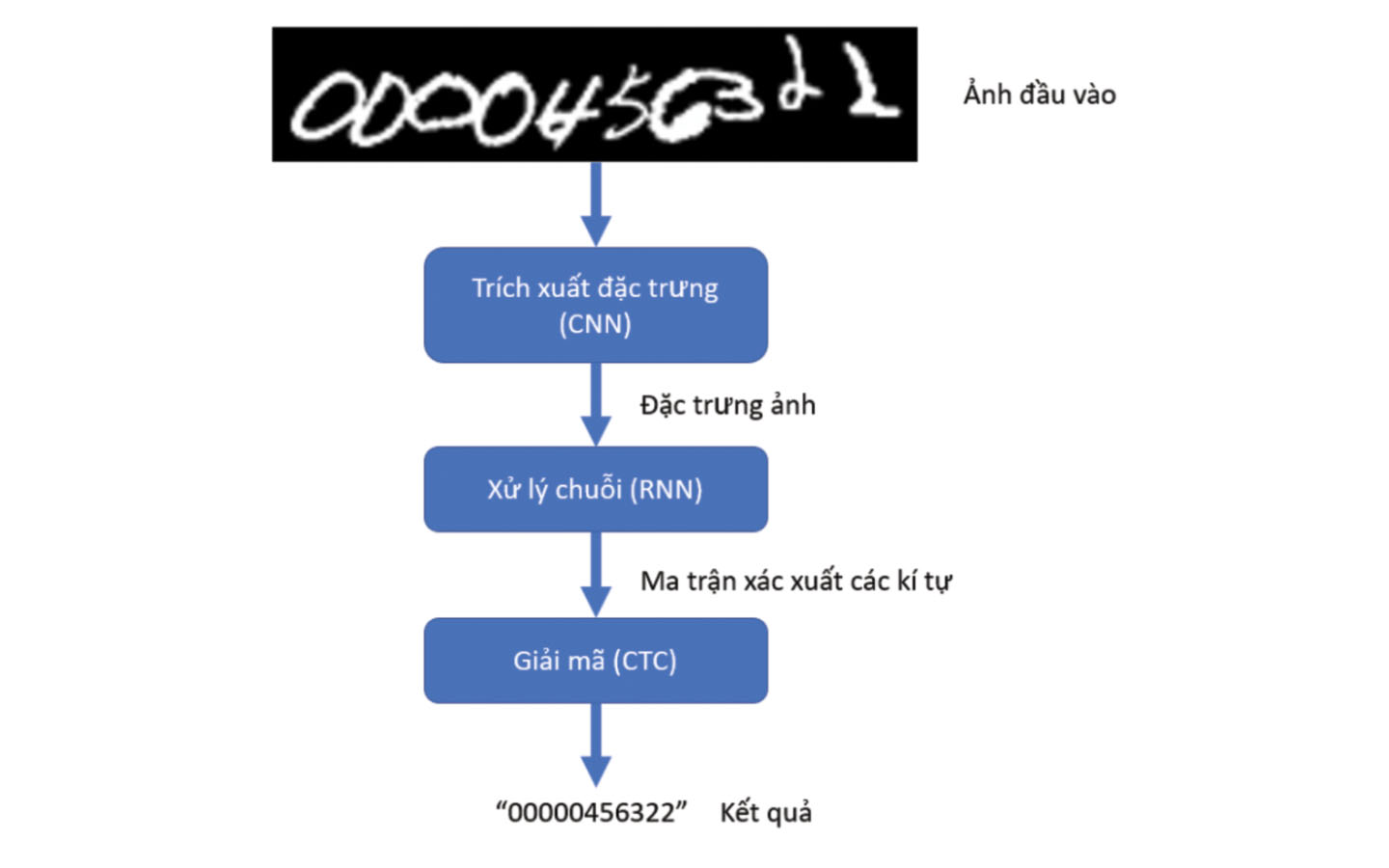
Hình 1 Luồng xử lý
Mô hình ở hình 1 sẽ có 3 phần, 3 giai đoạn, mỗi giai đoạn thì ảnh sẽ đi vào và được xử lý theo một cách khác nhau tương ứng với việc sử dụng convolutional layers (CNN), recurrent layers (RNN) và transcription (CTC). Đồng thời mô hình trên cũng sẽ có một tên gọi theo cách riêng của nó đó là Convolutional Recurrent Neural Network (CRNN).
Nếu bạn đã học xử lý ảnh thì quá trình này sẽ sử dụng một “nhân (kernel)” trượt trên toàn bộ ảnh đó giống như việc bạn dùng một chiếc đèn pin soi toàn bộ tấm ảnh vậy (có thể hiểu kernel ở đây chính là đèn pin), qua đó chiếc đèn pin sẽ thu được thông tin của tấm ảnh. CNN (convolutional neural network) cũng có cơ chế tương tự như vậy công dụng của một CNN trên ảnh là tìm kiếm những cái đặc trưng của tấm ảnh đó.
Từ đặc trưng đó, chúng ta cần xử lý để cho ra những khả năng, vị trí xuất hiện của kí tự trong ảnh. Recurrent Neural Network (RNN) sẽ xử lý công việc như vậy, nó thường được dùng trong các bài toán xử lý chuỗi như ngôn ngữ tự nhiên, dự đoán giá trị mới theo thời gian (giá nhà, thời tiết…) mà đặc điểm chung của những dữ liệu này là tuần tự. RNN sẽ tìm hiểu xem các đặc tính của ảnh có sự liên quan nào với nhau hoặc tồn lại quy luật nào đó giữa chúng hay không? Ví dụ như là hình dạng, kích thước, vị trí của đối tượng trong ảnh. Long Short Term Memory (LSTM) là một biến thể của RNN với nhiều hơn những cải tiến giúp cho mạng mang nhiều ưu điểm vượt trội so với RNN thông thường. Tuy nhiên, LSTM chỉ suy luận thông tin theo một chiều, sử dụng những ngữ cảnh trước để suy luận ra thông tin sau ví dụ như trong dự đoán giá nhà chẳng hạn, giá dự đoán sẽ chỉ dựa vào giá của các thời điểm trong quá khứ. Vì lý do đó mà nếu sử dụng LSTM trong nhận diện kí tự ảnh thì độ chính xác sẽ không cao do kí tự ở một vị trí xác định rất có thể bị phụ thuộc vào 2 kí tự liền kề (cả trước và sau). Vì vậy, một ý tưởng để cải thiện tình trạng đó là sẽ làm cho mạng LSTM này có thể suy luận thông tin cả 2 chiều, Bidirectional LSTM (bi-LSTM) ra đời bằng việc kết hợp 2 lớp LSTM lại với nhau. Hơn nữa, chúng ta hoàn toàn có thể xếp nhiều bi-LSTM lại với nhau tạo ra mạng lớn và sâu hơn (deep bidirectional LSTM), cấu trúc sâu hơn này cho phép hiểu thông tin nhiều hơn.
Cuối cùng chúng ta cần một thuật toán để giải mã những thông tin đó ra chữ. Transcription đóng vai trò như là một phiên dịch viên với việc áp dụng thuật toán Connectionist Temporal Classification (CTC). CTC sẽ có 2 công dụng, thứ nhất, nó sẽ được dùng để giải mã thông tin của ảnh sau khi đi qua RNN. Thứ hai, nó sẽ được sử dụng để tính giá trị lỗi (loss value). Trong bài này tôi sẽ chỉ nói phần giải mã thôi, còn tính giá trị lỗi là ở phần huấn luyện mô hình trên bộ dữ liệu nên tôi sẽ để trong bài sau.
Để giải mã ma trận xác suất của mạng, thì thuật toán sẽ lấy kí tự có khả năng xuất hiện (score) cao nhất ở mỗi phần (timestep), sau đó loại bỏ các kí tự lặp lại cũng như tất cả các khoảng trống và cho ra chuỗi đầu cuối. Kĩ thuật này còn được gọi là Best Path Decoding. Còn về xác suất của nhãn này cũng sẽ bằng tích của xác suất của kí tự ở mỗi phần (timestep) lại với nhau.
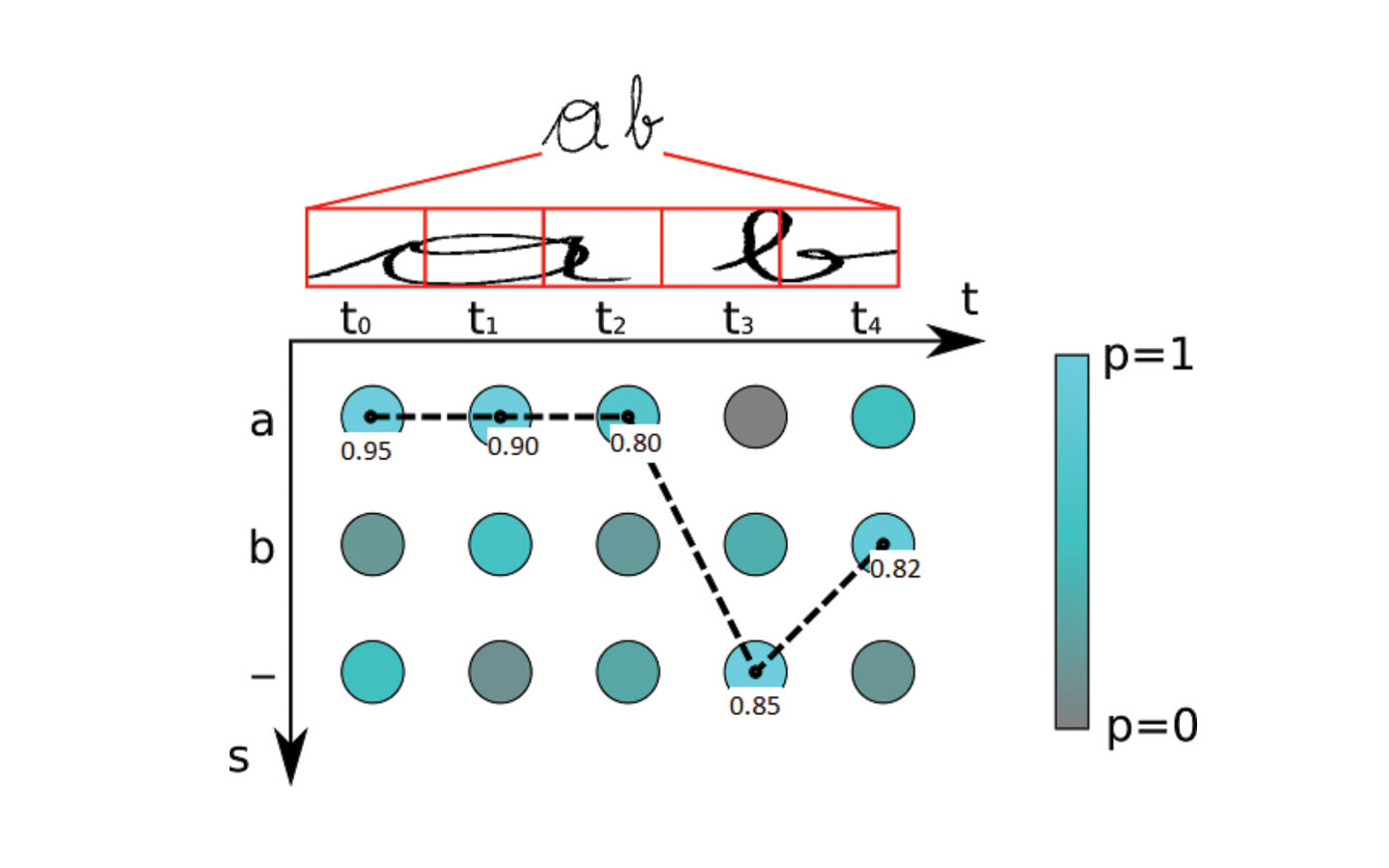
Hình 2 Giải mã
Ở hình 2 , chúng ta có một đồ thị 2 trục với phương ngang thể hiện cho chiều dài timestep (khái niệm rất đặc trưng trong LSTM, với bài toán này thì có thể hiểu một cách đơn giản là chia hình ảnh ra thành nhiều phần) và phương còn lại thể hiện cho xác suất có thể xuất hiện của kí tự trên mỗi timestep. Cũng qua đó mà ta có nhãn cuối là “aaa-b” và xác suất của nhãn này sẽ là 0.95*0.90*0.80*0.85*0.82 = 0.476, đồng thời sau khi loại bỏ các kí tự trùng lắp và khoảng trắng thì kết quả cuối cùng của nhãn sẽ là “ab”.
Phần transcription sẽ có 2 loại mô hình đó là lexicon-free và lexicon-based. Có thể hiểu là kết quả dự đoán sẽ bị một trong hai phương thức đó ràng buộc bằng một luật nào đó. Lexicon có nghĩa là “từ điển”, từ đó suy luận ra lexicon-free là chuỗi dự đoán ra không bị ràng buộc bởi bất kì thứ gì, còn lexicon-based thì ngược lại. Ở lexicon-based thì nó sẽ xem xét kết quả mã hóa có thuộc tập từ điển hay không nếu có thì kết quả được chấp nhận, còn không thì sẽ chọn lựa từ nào trong từ điển giống với kết quả mã hóa nhất.
Mô hình CRNN có một vài đặc tính nổi bật như sau (theo bài báo 1507.05717): 1) Ưu điểm của nó là có thể trực tiếp học từ chuỗi kí tự (từng từ) mà không cần phải đánh nhãn một cách quá chi tiết (từng kí tự). 2) Nó có tính năng của mạng CNN đó là học thông tin đặc trưng của tấm ảnh. 3) Nó cũng có đặc trưng của RNN là có khả năng xử lý và tạo ra chuỗi dữ liệu (kí tự). 4) Chuỗi kí tự dự đoán có thể dài ngắn khác nhau.
Trên thực tế, CRNN còn được ứng dụng cho khá là nhiều mục đích như là speech to text, phân loại âm thanh… Hầu như trong số chúng đều thể hiện ra việc cần phải xử lý đặc trưng của dữ liệu và xử lý chuỗi. Hiện nay CRNN cũng được sử dụng rất nhiều lĩnh vực khác nhau và không ngừng được cải tiến và hoàn thiện hơn.
(Bài viết này được tham khảo chủ yếu từ bài báo 1507.05717 “An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition” của tác giả Baoguang Shi, Xiang Bai, Cong Yao)
R&D Center.

