
画像上での文字認識 ((optical character recognition、OCR) は、テキスト コンテンツを含む写真をOCR プログラムが読み取って文字を返し、それをコンピューターによりコピー&ペーストできることを指します。
このプログラムの実行には、APIまたはTesseract のエンジンなど、多くのメソッドを使用することができます。 ここでは、人工知能のディープラーニングを使用した場合を記します。
当然のことながら、このディープラーニングを使用して画像上の文字を認識するプログラムの内部はどうなっているのかという質問があるでしょう。 ここでは、画像処理によって情報を取得し、その情報から文字情報を生成するという作業を行います。しかし、このような情報はコンピュータにしか理解できず、一般の人には理解できません。したがって、最後のステップでは、アルゴリズムを使用して、目的に沿うような結果が出るようデコードを行います。
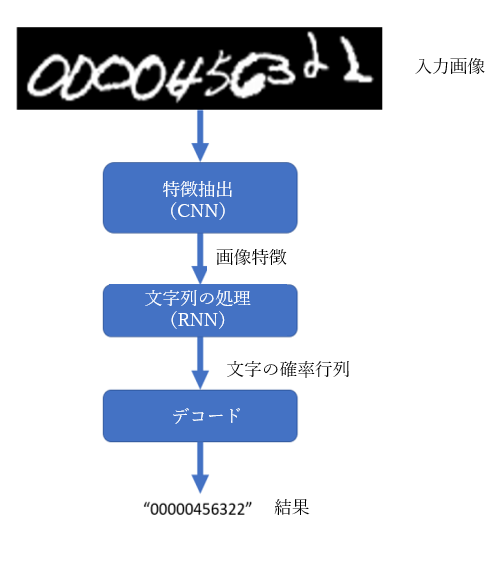
図1:処理フロー
図 1 のモデルでは3 つの段階があり、それぞれの段階で、convolutional layers (CNN)、recurrent layers (RNN)、transcription (CTC) を使用してそれぞれ異なる方法で処理されます。 また、上記のモデルはConvolutional Recurrent Neural Network (CRNN) という名前でも呼ばれています。
画像の学習では、このプロセスで、懐中電灯を使用して画像を見るのと同じように、「カーネル(kernel)」を使用してそれを画像全体にスライドさせます (ここでのカーネルは懐中電灯であると理解すればよいです)。CNN (convolutional neural network) にも同様のメカニズムがあり、画像上の特徴を探します。
その特徴を処理することにより、画像内で文字の可能性があるところを特定します。Recurrent Neural Network (RNN) がこのような処理を行います。これは、時間が経過することにより変わる値 (住宅価格、天気など) を予測することや自然言語などの文字列処理で使用されています。RNN は、画像の特徴が相互に関連しているか、あるいはそれらの間に何らかの規則性があるかを調べます。例としては、画像内のオブジェクトの形状、サイズ、位置などがあげられます。Long Short Term Memory (LSTM) は、多くの改良が加えられた RNN の一種で、一般の RNN に比べて多くの利点を持っています。
ただし、LSTM は一方向のみの推論であり、過去のコンテキストを使用して次の情報を推論しています。たとえば、住宅価格を予測する場合、予測価格は過去の価格に基づいています。 そのため、画像の文字認識にLSTMを使用すると、文字の認識が前後に隣接する2つの文字に依存してしまうため、精度は高くありません。したがって、これを改善するために、このLSTM ネットワークが両方向に推論できるよう、LSTM の 2 つの層を組み合わせてBidirectional LSTM (bi-LSTM) を生じさせます。さらに、複数のbi-LSTMを組み合わせることにより、より大きくて深いネットワーク(deep bidirectional LSTM) を作成することができ、これにより、より多くの情報を認識できるようになります。
最終的には、これらの情報を文字に変換するアルゴリズムが必要になります。 転写(Transcription)は、Connectionist Temporal Classification (CTC)アルゴリズムを適用したインタープリターとして機能します。 CTC には 2 つの用途があり、まずは、RNN で処理した後の画像情報をデコードすることであり、 次は、損失値(loss value)の計算に使用されることです。本稿ではデコード部分のみを説明することとし、損失値の計算はデータセット上のモデルのトレーニング部分となるため、次回に説明します。
ネットワークでの確率行列をデコードするために、アルゴリズムは各ステップ (timestep) で最も可能性の高い文字 (score) を取得し、繰り返されている文字とすべてのスペースを破棄し、最終文字列を出力します。この手法は、Best Path Decodingと呼ばれます。全体としての確率は各ステップ(タイムステップ)における文字ごとの確率の積になります。
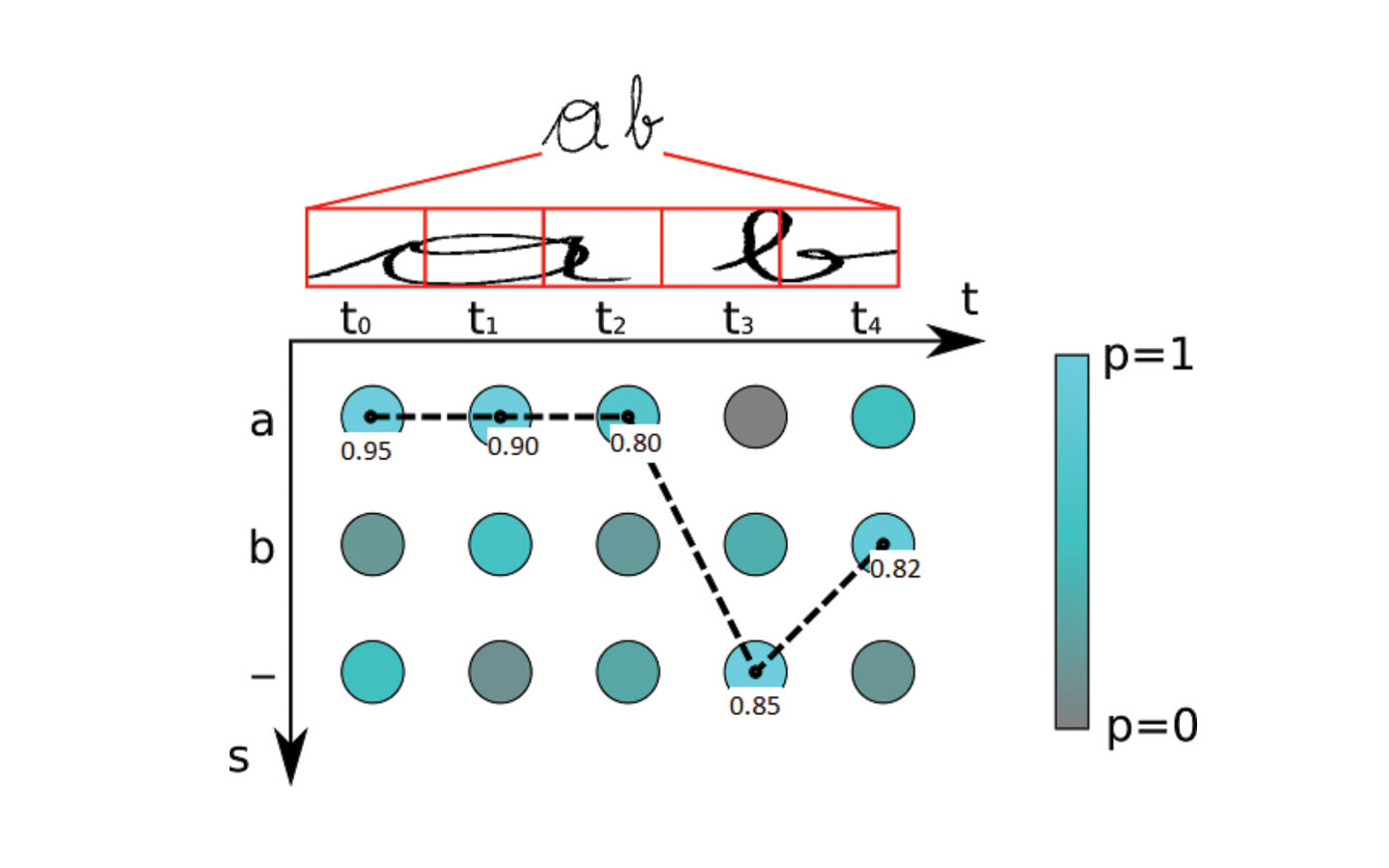
図2:デコード
図 2 のグラフには 2 軸があり、水平軸はタイムステップを表し (LSTM における典型的な概念であり、この問題では単に画像をいくつかの部分に分割していると理解すればよいです)、もう一方の軸はタイムステップごとの文字の確率を表します。これにより、最終的なラベルは「aaa-b」となり、確率としては0.95*0.90*0.80*0.85*0.82 = 0.476となって、重複文字とスペースが削除され、最終結果は“ab”になります。
Transcriptionには、lexicon-free とlexicon-basedの 2 種類のモデルがあります。どちらの手法でも予測結果は一定の法則によって導き出されます。 Lexicon は「辞書」を意味し、そこから、lexicon-free はなにも束縛されていない予測文字列であり、lexicon-based はその逆になります。Lexicon-basedでは、エンコード結果が辞書に存在しているかどうかを検証し、辞書に存在している場合には結果を受け入れ、そうでない場合には、最も類似している辞書内の文字を選択します。
CRNN モデルには、次のような特徴があります (記事 1507.05717 より)。
1) あまり詳細にラベル付けすることなく、文字列から (単語ごとに) 直接学習できることが利点です。
2) 画像の特徴を学習するというCNNネットワークの特徴を持っています。
3)文字列を処理・生成可能というRNNの特徴も持っています。
4) 予測文字列の長さが異なっている場合があります。
実際、CRNN は音声テキスト変換、音声分類など多くの目的で使用されています。その中でデータの特徴処理や文字列処理の必要性が示されています。 現在、CRNN はさまざまな分野で使用されており、常に改良されています。
(この記事は、Baoguang Shi、Xiang Bai、Cong Yao による 1507.05717「An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition」を参照しました。)
R&D Center.

